Before we proceed further, in the above corollary, we observe that the property of a linear function was used only in a small part of the proof of corollary 8 in last post. However, observe that the proof (for maximum) would follow through if the function  satisfies the following properties:
satisfies the following properties:
 ,
, 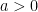 .
.- sub-additive property:

Such functions are called as sub-additive functions. So a sub-additive function which is continuous achieves its maximum on a vertex of a compact convex set. An example of sub-additive function is the norm 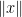 . Another example is the support function of a set (we will look at this function later).
. Another example is the support function of a set (we will look at this function later).
We will now look at some interesting examples of extreme points and maximization of linear functionals. We will first begin with the following motivational example.
Examples:
Assignment problem (AP): The AP arises in many contexts and is an example of binary optimization. Here we will motivate the problem in the context of wireless and later generalize the notion.
OFDM (orthogonal frequency division multiplexing) is a multi-carrier modulation which is being used in 4G networks. In OFDM,the data is modulated over different tones in such a way that orthogonality can be maintained across tones.
In general, a BS tower serves multiple users. When using OFDM, the BS generally has to decide the allocation of different tones to different users (OFDMA). Assume for now there are  frequency tones and there are users. In general the users are distributed in space. Hence each frequency tone will have a different “channel” with respect a user. So let
frequency tones and there are users. In general the users are distributed in space. Hence each frequency tone will have a different “channel” with respect a user. So let 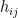 denote the channel of tone
denote the channel of tone  from the BS to the user
from the BS to the user  . A good channel in general indicates a higher data rate on that particular tone. A simple map from the channel quality to the data rate obtained is
. A good channel in general indicates a higher data rate on that particular tone. A simple map from the channel quality to the data rate obtained is  . So the BS wants to allocate one frequency tone per user and allocate all the tones, such that the sum rate is maximized. For example if
. So the BS wants to allocate one frequency tone per user and allocate all the tones, such that the sum rate is maximized. For example if 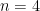 , a sample allocation is given by
, a sample allocation is given by  , which implies the first tone is allocated to the third user, the second tone to the second user, the third to the fourth user and the fourth to the first user. Observe that any allocation is just a permutation of the integers
, which implies the first tone is allocated to the third user, the second tone to the second user, the third to the fourth user and the fourth to the first user. Observe that any allocation is just a permutation of the integers  . So mathematically the BS should find a permutation
. So mathematically the BS should find a permutation  such that the allocated sum rate
such that the allocated sum rate

is maximized. Observe that if the BS has check for every permutation of  before it can find the permutation that maximizes the sum rate. Suppose there are
before it can find the permutation that maximizes the sum rate. Suppose there are  tones, then the search space is approximately
tones, then the search space is approximately  which is huge.
which is huge.
In a little while using the extreme points and Krein-Milman theorem, we will come up with a smarter way of solving this problem in polynomial complexity.
We will now start looking more closely at the vertices (extreme points) of a polyhedron. Most of the material is taken from AB. We will first begin with the following theorem that characterizes the vertices of a polyhedron in terms of linear dependence of the vectors.
Proof: Let us first prove that vertex implies linear span. We will prove by contradiction.Let  be a vertex of
be a vertex of  . Suppose
. Suppose  does not span
does not span  . For notation let the cardinality of
. For notation let the cardinality of  be
be  Consider the matrix
Consider the matrix  with
with  as the columns, \ie,
as the columns, \ie,
![\displaystyle A=[a_1,... ,a_m],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+A%3D%5Ba_1%2C...+%2Ca_m%5D%2C&bg=ffffff&fg=000000&s=0&c=20201002)
an  matrix. Since does not span the entire , the kernel space (or null space) of the matrix is non empty (or the dimension of the kernel is greater than
matrix. Since does not span the entire , the kernel space (or null space) of the matrix is non empty (or the dimension of the kernel is greater than  .) Hence there exists a non zero
.) Hence there exists a non zero  . Since ,
. Since ,

We will now prove that is not a vertex. Let 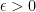 be a small number. Define
be a small number. Define

and

Observe that  and hence if
and hence if  and
and  lie in the polyhedron , then is not an extreme point (vertex) which is a contradiction. We will now prove that for very small
lie in the polyhedron , then is not an extreme point (vertex) which is a contradiction. We will now prove that for very small  , and indeed lie in . To show that (or ) lie in we should show that they satisfy
, and indeed lie in . To show that (or ) lie in we should show that they satisfy  for all . Let
for all . Let  . Then
. Then

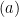 follows since
follows since  for
for  and
and  since . Now if
since . Now if  , then
, then

Observe that  . Hence if we choose very very small, then
. Hence if we choose very very small, then  . (For example, you can choose
. (For example, you can choose  .). Hence satisfies all the inequalities and hence is in the polyhedron. Similarly, you can show that satisfies all the inequalities and hence in the polyhedron.
.). Hence satisfies all the inequalities and hence is in the polyhedron. Similarly, you can show that satisfies all the inequalities and hence in the polyhedron.
We will now prove the converse, \ie, linear span implies vertex. Suppose  where
where  . We first have for ,
. We first have for ,

Since , we have  and
and  , which is possible only when
, which is possible only when  and
and  . Now consider the set of equations for .
. Now consider the set of equations for .

Since span the entire , it follows that there is a unique solution to the above set of equations. However, we have and and . This implies  since the solution should be unique.
since the solution should be unique. 
Corollary 2 For any vertex
, the cardinality of the set
should be greater than

, \ie

.
Proof: We require at least vectors to span .
We will now analyze a particular polyhedron that is required to simplify the assignment problem. Before that we require the following definition of a permutation matrix. Suppose is a permutation of . Then the permutation matrix  is an
is an 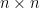 matrix with the
matrix with the 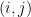 entry given by
entry given by

So for a given there are  permutation matrices.
permutation matrices.
Birkhoff polytope:
Birkhoff polytope  is the set of all doubly stochastic matrices. Mathematically,
is the set of all doubly stochastic matrices. Mathematically,

First observe that is entirely defined by linear inequalities and hence a polyhedron. Also observe that is a convex set.
Hw 1 Show that
is a compact set.
Lemma 3 An

permutation matrix
is an extreme point of
.
Proof: Suppose  where
where  . Consider the -th row of all the three matrices. Suppose
. Consider the -th row of all the three matrices. Suppose  and all the other entries are zero. So we have
and all the other entries are zero. So we have
![\displaystyle 2[0, 0, ..,1,....0] = [a_{i1}, ..., a_{in}]+[c_{i1}, ..., c_{in}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+2%5B0%2C+0%2C+..%2C1%2C....0%5D+%3D+%5Ba_%7Bi1%7D%2C+...%2C+a_%7Bin%7D%5D%2B%5Bc_%7Bi1%7D%2C+...%2C+c_%7Bin%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002)
We have  ,
,  and each term is non-negative. This is possible only when
and each term is non-negative. This is possible only when  and zero for all the other entries of the -th row. This shows that
and zero for all the other entries of the -th row. This shows that  , which proves that is an extreme point of .
, which proves that is an extreme point of .
We will now prove the converse of the above statement.
Theorem 4 (Birkhoff- von Neumann Theorem.) The extreme points of are precisely the set of permutation matrices.
Proof: We prove the lemma by induction. For  , it is an obvious statement. Let us assume it is true till dimension
, it is an obvious statement. Let us assume it is true till dimension 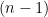 and prove it for dimension .
and prove it for dimension .
Consider the following affine subspace of  . The space
. The space  is the set of all
is the set of all 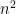 real numbers
real numbers  such that
such that

and

Observe that the dimension of the space is  . (Think why??) Observe that
. (Think why??) Observe that  and is defined as the polyhedron
and is defined as the polyhedron

in .
Let be an extreme point of . So by Theorem 1, an extreme point of should satisfy at least inequalities with equalities. Hence  for at least entries of the matrix. We make the following observation.
for at least entries of the matrix. We make the following observation.
- Every row cannot have more than or equal to
 non zero entries: In this case the maximum number of zero entries would be
non zero entries: In this case the maximum number of zero entries would be  (each row can have at maximum
(each row can have at maximum 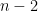 zero entries and there are rows). This cannot be true, since
zero entries and there are rows). This cannot be true, since  .
.
So there is at least one row  with only one non-zero entry at
with only one non-zero entry at  location. Since is also doubly stochastic, we have that
location. Since is also doubly stochastic, we have that  . Hence it also follows that there can be no more non zero entries in the column . Let
. Hence it also follows that there can be no more non zero entries in the column . Let  be the new matrix obtained after removing the row and the column . Observe that
be the new matrix obtained after removing the row and the column . Observe that
- is a doubly stochastic matrix:This is because the original matrix was doubly stochastic and the contribution from row and column is only
 .
.
- is an extreme point of
 : Suppose is not an extreme point of , \ie, can be expressed as a sum of
: Suppose is not an extreme point of , \ie, can be expressed as a sum of  , where
, where  and
and  . Then it is easy to see that by adding one more row (all zeros except at ) and column (all zeros except at ) to
. Then it is easy to see that by adding one more row (all zeros except at ) and column (all zeros except at ) to  and
and  at positions and will result in new matrices
at positions and will result in new matrices  and
and  . Observe that
. Observe that  .
.
So is an extreme point of . So by induction hypothesis, we have that is some  permutation matrix . Now augment with the row and column to obtain .
permutation matrix . Now augment with the row and column to obtain .
We will now see how to utilize this theorem to simplify the assignment problem. Recall that the AP was to minimize over all the permutations of .

Observe that the cost function  is equivalent to
is equivalent to

where  is the permutation matrix. So the AP equals
is the permutation matrix. So the AP equals

Observe that even now, 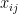 is restricted to be either or
is restricted to be either or  .
.
Now consider a new problem P2:

over the set

Observe that we are now maximizing over the Birkhoff polytope and  are real numbers. So we are maximizing a linear function
are real numbers. So we are maximizing a linear function  over a convex compact set . Hence the maximum occurs at a vertex point of . But by Birkhoff- von Neumann theorem, the vertices of are nothing but the permutation matrices. Hence solving P2 is equal to solving AP. Also observe that the new problem P2 is a linear programming problem and is very easy to solve in polynomial complexity.
over a convex compact set . Hence the maximum occurs at a vertex point of . But by Birkhoff- von Neumann theorem, the vertices of are nothing but the permutation matrices. Hence solving P2 is equal to solving AP. Also observe that the new problem P2 is a linear programming problem and is very easy to solve in polynomial complexity.





 is the iteration number.
is the iteration number. 


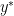





![\displaystyle \begin{array}{rcl} (2+s/2)\delta_{s+1}-(1+s/2)\delta_s\leq & \frac{\beta}{2}(2+s/2)\|y_{s+1}-x_s\|^2\\ &+\nabla f(x_s)^T\left[(1+s/2)(y_{s+1}-y_s)+(y_{s+1}-y^*)\right]. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%282%2Bs%2F2%29%5Cdelta_%7Bs%2B1%7D-%281%2Bs%2F2%29%5Cdelta_s%5Cleq+%26+%5Cfrac%7B%5Cbeta%7D%7B2%7D%282%2Bs%2F2%29%5C%7Cy_%7Bs%2B1%7D-x_s%5C%7C%5E2%5C%5C+%26%2B%5Cnabla+f%28x_s%29%5ET%5Cleft%5B%281%2Bs%2F2%29%28y_%7Bs%2B1%7D-y_s%29%2B%28y_%7Bs%2B1%7D-y%5E%2A%29%5Cright%5D.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)



![\displaystyle \begin{array}{rcl} \frac{\beta}{2}\|(2+s/2)(y_{s+1}-x_s)\|^2\\ +(2+s/2)\nabla f(x_s)^T\left[(1+s/2)(y_{s+1}-y_s)+(y_{s+1}-y^*)\right]. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%5Cfrac%7B%5Cbeta%7D%7B2%7D%5C%7C%282%2Bs%2F2%29%28y_%7Bs%2B1%7D-x_s%29%5C%7C%5E2%5C%5C+%2B%282%2Bs%2F2%29%5Cnabla+f%28x_s%29%5ET%5Cleft%5B%281%2Bs%2F2%29%28y_%7Bs%2B1%7D-y_s%29%2B%28y_%7Bs%2B1%7D-y%5E%2A%29%5Cright%5D.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)



![\displaystyle \begin{array}{rcl} \frac{\beta}{2}\left[ \|(1+s/2)(x_s-y_s) +(x_s-y^*)\|^2\right.\\ \left.-\|(1+s/2)(x_s-y_s)-(2+s/2)(x_s-y_{s+1}) +(x_s-y^*) \| \right] \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%5Cfrac%7B%5Cbeta%7D%7B2%7D%5Cleft%5B+%5C%7C%281%2Bs%2F2%29%28x_s-y_s%29+%2B%28x_s-y%5E%2A%29%5C%7C%5E2%5Cright.%5C%5C+%5Cleft.-%5C%7C%281%2Bs%2F2%29%28x_s-y_s%29-%282%2Bs%2F2%29%28x_s-y_%7Bs%2B1%7D%29+%2B%28x_s-y%5E%2A%29+%5C%7C+%5Cright%5D+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)


![\displaystyle \begin{array}{rcl} \frac{\beta}{2}\left[ \| (2+s/2)x_s-(1+s/2)y_s-y^*\|^2\right.\\ \left.-\| (2+(s+1)/2)x_{s+1}-(1+(s+1)/2)y_{s+1}-y^* \| \right] \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%5Cfrac%7B%5Cbeta%7D%7B2%7D%5Cleft%5B+%5C%7C+%282%2Bs%2F2%29x_s-%281%2Bs%2F2%29y_s-y%5E%2A%5C%7C%5E2%5Cright.%5C%5C+%5Cleft.-%5C%7C+%282%2B%28s%2B1%29%2F2%29x_%7Bs%2B1%7D-%281%2B%28s%2B1%29%2F2%29y_%7Bs%2B1%7D-y%5E%2A+%5C%7C+%5Cright%5D+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)


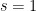















.
,


 , when used on
, when used on  , when used on the
, when used on the 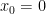 and
and  Span
Span
 and
and  . There exists a
. There exists a 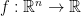 such that for any black-procedure satisfying the conditions defined above,
such that for any black-procedure satisfying the conditions defined above,

 , let
, let  be the symmetric and tridiagonal matrix defined by
be the symmetric and tridiagonal matrix defined by 
 . The first inequality can be verified as follows.
. The first inequality can be verified as follows. 
 . Observe that from our assumption
. Observe that from our assumption  and hence
and hence  is well defined. We consider now the following
is well defined. We consider now the following  smooth convex function:
smooth convex function: 
 is not the running index of the algorithm. First we fix a
is not the running index of the algorithm. First we fix a 
 , we can represent
, we can represent  ,
, 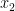 ,
,  , as follows,
, as follows, 
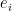 is the standard basis (it has
is the standard basis (it has  . Similarly,
. Similarly, ![\displaystyle \begin{array}{rcl} x_2&=& x_1- \left(\nabla f(x_1)\right) \\ &=& x1-\left[\left(\frac{\beta}{4}\left(A_{2t+1}\right)\left(x_0-\frac{\beta}{4}e_1\right)\right)-\frac{\beta}{4}e_1\right], \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++x_2%26%3D%26+x_1-+%5Cleft%28%5Cnabla+f%28x_1%29%5Cright%29+%5C%5C+%26%3D%26+x1-%5Cleft%5B%5Cleft%28%5Cfrac%7B%5Cbeta%7D%7B4%7D%5Cleft%28A_%7B2t%2B1%7D%5Cright%29%5Cleft%28x_0-%5Cfrac%7B%5Cbeta%7D%7B4%7De_1%5Cright%29%5Cright%29-%5Cfrac%7B%5Cbeta%7D%7B4%7De_1%5Cright%5D%2C+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
 . From the way,
. From the way,  is defined, it is easy to verify that
is defined, it is easy to verify that  must lie in the linear span of
must lie in the linear span of  . In particular for
. In particular for  we necessarily have
we necessarily have  for
for  , which implies
, which implies 


 and from the definition of
and from the definition of  we can see,
we can see,  . The inequality
. The inequality 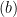 follows since
follows since  . We now compute the minimizer
. We now compute the minimizer  of
of  , its norm, and the corresponding function value
, its norm, and the corresponding function value  . The optimal
. The optimal  . i.e.,
. i.e.,  . So, the point
. So, the point  of
of  . It is easy to verify that it is defined by
. It is easy to verify that it is defined by  for
for  . Thus we immediately have:
. Thus we immediately have: 
 . So we have
. So we have 


 be the number of iterations required to achieve an error of less than
be the number of iterations required to achieve an error of less than 
 , we have that the upperbound is the square(up to a constant) of the lower bound. However, for small
, we have that the upperbound is the square(up to a constant) of the lower bound. However, for small  . There exists a
. There exists a 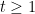 one has
one has

 . This means for large values of Q:
. This means for large values of Q: 
 in the denominator of the exponent.
in the denominator of the exponent.
 be continuous and differentiable. Using Taylor Series, we get
be continuous and differentiable. Using Taylor Series, we get 
 term. The descent direction is defined in two steps. First, we look at the so-called normalized steepest descent direction. This in turn helps us define the steepest descent direction. The normalized steepest descent direction is defined as
term. The descent direction is defined in two steps. First, we look at the so-called normalized steepest descent direction. This in turn helps us define the steepest descent direction. The normalized steepest descent direction is defined as 
 , but also on the norm
, but also on the norm  . As is clear from the definition, the name normalized is used since we are searching only through those vectors that have unit magnitude. Looking closely, we notice that this definition is similar to the one of dual norm of a given norm. Hence, the minimum value is given by
. As is clear from the definition, the name normalized is used since we are searching only through those vectors that have unit magnitude. Looking closely, we notice that this definition is similar to the one of dual norm of a given norm. Hence, the minimum value is given by  . The negative sign compensates for the “min” used here as opposed to the “max” used in the definition of a dual norm. Now we can define the descent direction for the Steepest Descent Algorithm as follows:
. The negative sign compensates for the “min” used here as opposed to the “max” used in the definition of a dual norm. Now we can define the descent direction for the Steepest Descent Algorithm as follows: 
 term used in the definition:
term used in the definition: 


 , where
, where 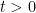 ,
,  and jointly optimizing over
and jointly optimizing over  .
.  . The quadratic norm of any vector
. The quadratic norm of any vector  is then defined as
is then defined as

 =
=  , then this essentially corresponds to a change of basis. Since
, then this essentially corresponds to a change of basis. Since  is well defined. This in turn lets us allow the quadratic expression to be simplified as follows:
is well defined. This in turn lets us allow the quadratic expression to be simplified as follows: 



 can be chosen to be equal to
can be chosen to be equal to  . This would improve the condition number and the convergence rate of the algorithm.
. This would improve the condition number and the convergence rate of the algorithm.  strongly convex. Then Steepest Descent with Back Tracking has a linear convergence rate.
strongly convex. Then Steepest Descent with Back Tracking has a linear convergence rate. 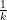 . In this lecture, we present a GD algorithm with constant step size for
. In this lecture, we present a GD algorithm with constant step size for  satisfies
satisfies

 . Since
. Since 

 as follows:
as follows: 


 the last term in the RHS can be neglected and we obtain the following upper bound.
the last term in the RHS can be neglected and we obtain the following upper bound. 


 , it follows from Theorem
, it follows from Theorem 
 on an
on an 

 in Theorem
in Theorem 
 .
.  type of convergence is called as linear convergence and
type of convergence is called as linear convergence and  convergence is called as quadratic convergence. It can be seen that the rate of convergence in the above theorem critically depends on the condition number
convergence is called as quadratic convergence. It can be seen that the rate of convergence in the above theorem critically depends on the condition number  imply slow convergence. The next lemma examines the convergence behaviour with diminishing step size.
imply slow convergence. The next lemma examines the convergence behaviour with diminishing step size.  , we have
, we have

 , we have
, we have 
 . However for large
. However for large  . While this might slow down the initial steps of the algorithm, the convergence rate would still be given by Lemma
. While this might slow down the initial steps of the algorithm, the convergence rate would still be given by Lemma  for large
for large 
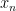 as the current point and
as the current point and  as the optimal point. Then
as the optimal point. Then  decreases with
decreases with  .
. 



 , then
, then 
 satisfies
satisfies 



 be
be  and
and  be
be  . Substituting this in the previous result we get,
. Substituting this in the previous result we get,




 and consequently
and consequently  . So
. So
 .
.
 ) we get,
) we get,
 , so
, so  . Thus we have
. Thus we have
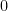 to
to  we get,
we get,
 ,
,  and thus
and thus  are positive numbers. Thus
are positive numbers. Thus
 maximizes
maximizes  and hence optimal.
and hence optimal. ,
,
 .
.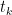 be such that
be such that  and
and  . Then GDA converges to the global optimum. In particular when
. Then GDA converges to the global optimum. In particular when  , we have
, we have

 to be well defined for large
to be well defined for large  , it can be shown that (by approximating the sum by a Riemannian integral)
, it can be shown that (by approximating the sum by a Riemannian integral)

 in the convergence rate compared to
in the convergence rate compared to ![Convergence rates of a quadratic function x'Mx for different step sizes. The EIG(M)=[1.09, 0.227,0]. Hence the Lipscitz constant is 1.09 and the function is also not strongly convex.](https://rkganti.wordpress.com/wp-content/uploads/2015/08/convergence_gda.jpg)
 as
as 
 for the algorithm to end,
for the algorithm to end,

 which shows that the convergence depends directly on the Lipschiz constant
which shows that the convergence depends directly on the Lipschiz constant 
 is a poor way to go through with optimization as will be explained in later lectures.
is a poor way to go through with optimization as will be explained in later lectures. ,
,

 ,
,

 . Then,
. Then,
 term since
term since  term, and
term, and 
 such that
such that  . We refer to such a sequence as a minimizing sequence. We next define a tolerance limit to the optimization problem which basically limits the allowed gap between the optimal value and the function value at the point returned by the algorithm. By this we mean that the algorithm stops at
. We refer to such a sequence as a minimizing sequence. We next define a tolerance limit to the optimization problem which basically limits the allowed gap between the optimal value and the function value at the point returned by the algorithm. By this we mean that the algorithm stops at 

 is the step size and
is the step size and  is the descent direction. Here,
is the descent direction. Here,  and hence it is not a “direction” in the strict sense of the word but a misnomer. By descent, we mean the following,
and hence it is not a “direction” in the strict sense of the word but a misnomer. By descent, we mean the following, 



 .
.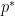 . As we will see later, the choice of stopping criterion is of prime importance to the performance of a descent algorithm and it is not easy to come up with an appropriate stopping criterion. For now, we assume that “Exact Line Search” is used. By this, we mean that the step size
. As we will see later, the choice of stopping criterion is of prime importance to the performance of a descent algorithm and it is not easy to come up with an appropriate stopping criterion. For now, we assume that “Exact Line Search” is used. By this, we mean that the step size 

 . Then the gradient descent algorithm with a constant step size
. Then the gradient descent algorithm with a constant step size  will converge to a stationary point, i.e., the set
will converge to a stationary point, i.e., the set  .
.





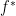 is the global optimal value. Taking the limit as
is the global optimal value. Taking the limit as  , we have
, we have
 and hence
and hence  .
.  maximizes
maximizes  term appearing in the denominator of
term appearing in the denominator of 
 . Then
. Then

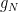 , i.e, the best gradient till
, i.e, the best gradient till  corresponding to the initial point is bounded.
corresponding to the initial point is bounded. is said to be Lipschitz if
is said to be Lipschitz if

 is Lipschitz with constant
is Lipschitz with constant 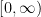 . The following theorem characterized Lipschitz functions which are differentiable.
. The following theorem characterized Lipschitz functions which are differentiable. 
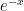 ,
,  .
.  =
= and
and  . Hence the Lipschitz constant of an exponential function is 1.
. Hence the Lipschitz constant of an exponential function is 1.

 . We have
. We have  and
and 




 i.e., if a function is
i.e., if a function is 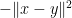 ) and hence very loose. Nevertheless, this shows that the growth rate of a
) and hence very loose. Nevertheless, this shows that the growth rate of a  is convex if
is convex if
![{f(\lambda x +(1-\lambda) y) \leq \lambda f(x) +(1-\lambda)f(y), \lambda \in [0,1]}](https://s0.wp.com/latex.php?latex=%7Bf%28%5Clambda+x+%2B%281-%5Clambda%29+y%29+%5Cleq+%5Clambda+f%28x%29+%2B%281-%5Clambda%29f%28y%29%2C+%5Clambda+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.

 , i.e., the Hessian is positive semi definite matrix for all
, i.e., the Hessian is positive semi definite matrix for all 

 is convex, it is not strongly convex. However (adding a regularisation term)
is convex, it is not strongly convex. However (adding a regularisation term)  is strongly convex. Similarly adding
is strongly convex. Similarly adding  to any convex function would lead to a strongly convex function. The next theorem provides a bound on the gap between the function value and the optimum in terms of the gradient.
to any convex function would lead to a strongly convex function. The next theorem provides a bound on the gap between the function value and the optimum in terms of the gradient. 
 , where
, where 

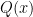 is a quadratic function of
is a quadratic function of 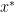 =
= Substituting this in (
Substituting this in (
 denote
denote  . As
. As  ,
,  .
.  . Hence we focus on a sub-class of optimization problems that can be solved efficiently.
. Hence we focus on a sub-class of optimization problems that can be solved efficiently.

 will be neglected. In most of the problems we will be considering,
will be neglected. In most of the problems we will be considering,  .
.![\displaystyle \min_{x\in [0,1]^n} f(x),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmin_%7Bx%5Cin+%5B0%2C1%5D%5En%7D+f%28x%29%2C&bg=ffffff&fg=000000&s=0&c=20201002)
 norm. We require an
norm. We require an  . A function
. A function  is Lipschitz continuous with constant
is Lipschitz continuous with constant 
 parts and search over the resulting lattice. It can easily be seen that
parts and search over the resulting lattice. It can easily be seen that  calls to the oracle are required.
calls to the oracle are required. , the grid search algorithm provides an
, the grid search algorithm provides an  be some vertex of the hypercube. Then by Lipschitz continuity of
be some vertex of the hypercube. Then by Lipschitz continuity of 
 , i.e.,
, i.e.,  , we obtain the required accuracy.
, we obtain the required accuracy.  times to obtain an
times to obtain an  steps.
steps. . The algorithm will provide a sequence of points
. The algorithm will provide a sequence of points  after which the algorithm outputs the optimal value with
after which the algorithm outputs the optimal value with  (otherwise we are done). Now since there are only
(otherwise we are done). Now since there are only 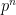 points in the square
points in the square ![{[0,1]^n}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%5En%7D&bg=ffffff&fg=000000&s=0&c=20201002) , there exists one point
, there exists one point ![{\tilde{x} \in [0,1]^n}](https://s0.wp.com/latex.php?latex=%7B%5Ctilde%7Bx%7D+%5Cin+%5B0%2C1%5D%5En%7D&bg=ffffff&fg=000000&s=0&c=20201002) such that
such that  (the ball is with respect to
(the ball is with respect to 
 . This function is non zero only when
. This function is non zero only when  , i.e., in the ball
, i.e., in the ball  . It is easy to see that algorithm that is designed will never get closer to the optimal value.
. It is easy to see that algorithm that is designed will never get closer to the optimal value.  be
be  . Let
. Let 
 define
define
